

In the rapidly evolving world of natural language processing (NLP), the Retrieval-Augmented Generation (RAG) model has emerged as a formidable paradigm. It offers a nuanced synthesis of retrieval and generation techniques, creating a hybrid model that leverages the best of both worlds. By facilitating the extraction of pertinent information from vast datasets while generating coherent responses, RAG models promise significant advancements in NLP tasks. This article provides a comprehensive guide to setting up a RAG pipeline efficiently, elucidating its components, benefits, and practical applications. Select the best RAG pipeline setup.
Understanding the RAG Pipeline
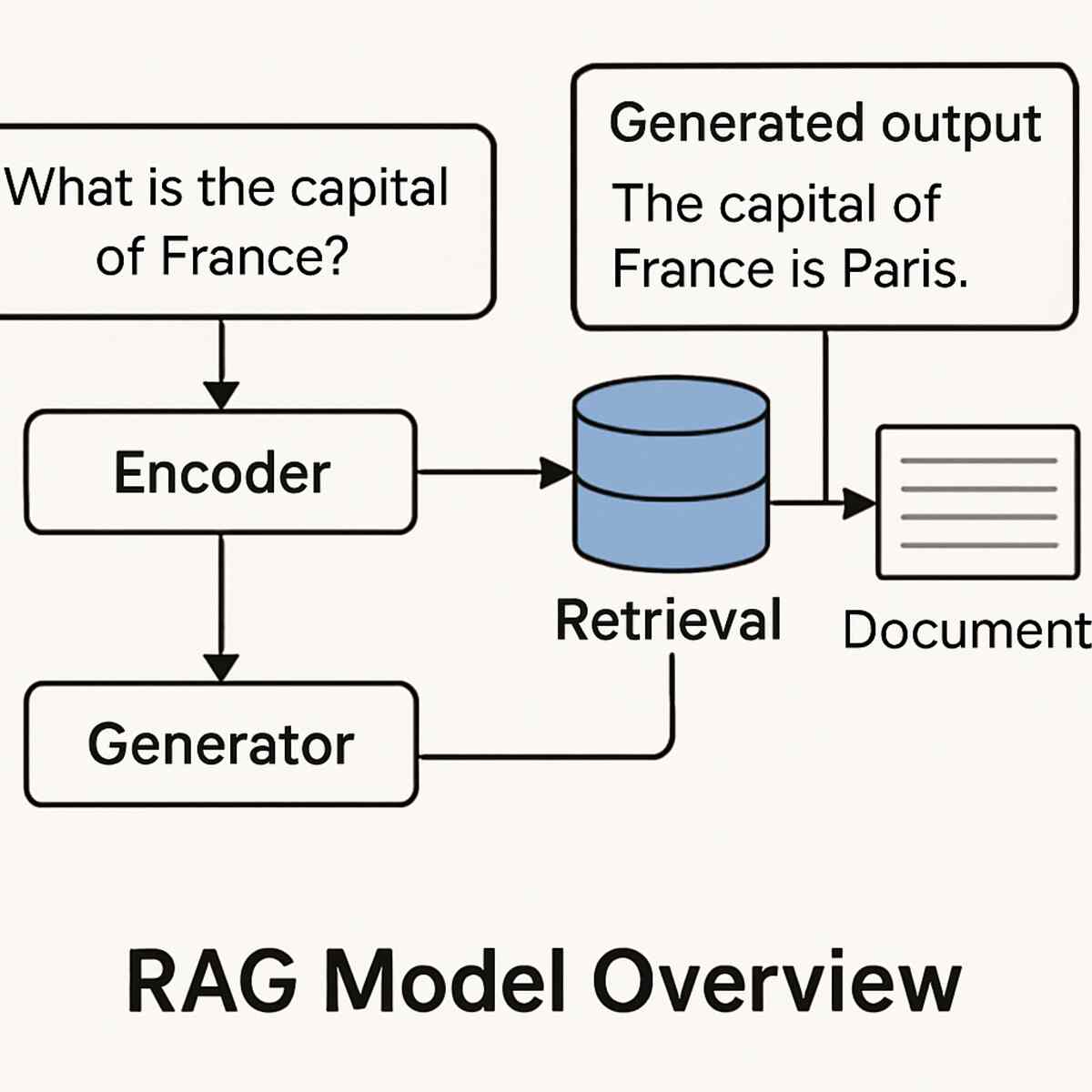
The RAG pipeline is characterized by its dual-phase architecture, consisting of a retrieval module and a generation module. This two-pronged approach is essential for extracting and synthesizing information effectively. The retrieval component is tasked with sourcing relevant documents from a predefined corpus, while the generation component synthesizes these inputs into a coherent output. This integration of retrieval and generation processes enables the RAG model to produce contextually enriched and informative responses.
Components of a RAG Pipeline
- Retrieval Module: The retrieval module employs sophisticated algorithms to search and fetch relevant documents from a vast corpus. This is achieved through vector similarity measures and advanced indexing techniques that ensure high retrieval accuracy. The choice of algorithm plays a pivotal role in balancing speed and precision, often necessitating a trade-off based on specific application needs. Additionally, the retrieval module must be capable of handling large volumes of data efficiently, making scalability a key consideration during setup.
- Generation Module: In the generation module, a generative model—typically based on transformer architectures like BERT or GPT—takes the retrieved documents and the original query to generate a human-like response. This module is pivotal in ensuring the output is coherent and contextually aligned with the input query. Fine-tuning these models on domain-specific data can significantly enhance their performance, allowing them to generate more relevant and precise responses. Moreover, maintaining a balance between creativity and factual accuracy is crucial for generating trustworthy outputs.
- Integration Layer: The integration layer serves as the nexus between retrieval and generation, managing the flow of information and ensuring seamless interaction between the two modules. It orchestrates the data transfer, ensuring that only the most pertinent information is passed to the generation module. This layer also includes mechanisms for error handling and data validation, ensuring robustness in the pipeline’s operation. Furthermore, it can incorporate feedback loops for continuous learning and improvement of the pipeline’s performance over time.
Benefits of a RAG Pipeline
The RAG pipeline’s architecture offers several advantages:
- Enhanced Contextual Awareness: By retrieving information from a vast corpus, the model generates responses that are both contextually enriched and accurate. This contextual awareness is crucial for applications that require nuanced understanding and interpretation of queries. It allows for more dynamic interactions, where the model can adapt its responses based on the evolving context of the conversation or task. Additionally, this feature enhances the model’s ability to handle ambiguous or incomplete queries by leveraging relevant background information.
- Scalability: The modular nature of the pipeline allows for easy scaling, accommodating larger datasets and more complex queries. This scalability is achieved through the independent operation of the retrieval and generation modules, which can be scaled separately based on demand. As data volumes grow, the pipeline can be expanded horizontally, adding more retrieval nodes or increasing computational resources for the generation module. This flexibility ensures that the RAG pipeline can adapt to changing workloads and data requirements efficiently.
- Versatility: The RAG model is adaptable to various domains, making it suitable for diverse applications ranging from customer support to academic research. This versatility stems from the model’s ability to incorporate domain-specific knowledge through fine-tuning and data enrichment. It can be customized to handle specific terminologies and content styles, making it highly effective in specialized fields. Furthermore, its application extends beyond text-based interactions, potentially encompassing multimodal data processing and integration.
Step-by-Step Guide to Setting Up a RAG Pipeline
Setting up a RAG pipeline involves meticulous planning and execution. Below is a detailed guide to facilitate this process.

Step 1: Data Preparation
Before delving into the technical setup, it is imperative to prepare your dataset. This involves cleaning and structuring your corpus to enhance retrieval efficiency. Ensure that your data is indexed appropriately to facilitate quick access and retrieval.
- Cleaning and Structuring Data: Begin by removing duplicate entries, irrelevant information, and noise from your dataset. This cleaning process is crucial for ensuring that the retrieval module functions with high precision, reducing the risk of irrelevant data affecting the generation output. Structuring data involves categorizing and tagging information to allow for efficient indexing and retrieval, aligning with the retrieval module’s requirements.
- Indexing for Efficient Retrieval: Properly indexing your data is essential for swift and accurate document retrieval. Utilize advanced indexing techniques like inverted indexes or tree-based structures to organize your data effectively. This allows for quick lookups and retrieval, which is critical for maintaining the RAG pipeline’s performance, especially under heavy query loads.
- Data Enrichment: Consider enriching your dataset with additional metadata, annotations, or context to enhance its quality. This enrichment can include semantic tagging, entity recognition, or linking related documents, which can improve the retrieval module’s ability to find the most relevant information. Enriched data also provides more context to the generation module, resulting in more informed and accurate responses.
Step 2: Configuring the Retrieval Module
The retrieval module is the cornerstone of the RAG pipeline. Begin by selecting an appropriate retrieval algorithm. Popular choices include BM25, FAISS, and Elasticsearch, each offering unique benefits in terms of speed and accuracy. Configure the algorithm to align with the specifics of your dataset, optimizing parameters for maximum retrieval efficiency.
- Selecting the Right Retrieval Algorithm: Choose an algorithm that aligns with your specific requirements, considering factors such as data size, query complexity, and desired retrieval speed. BM25 is well-suited for text-based retrieval, while FAISS excels in high-dimensional vector searches, and Elasticsearch offers robust full-text search capabilities.
- Parameter Optimization: Fine-tune the retrieval algorithm’s parameters to maximize efficiency and accuracy. This involves adjusting settings such as similarity thresholds, indexing strategies, and query expansion techniques. Regularly evaluate and refine these parameters based on performance metrics and feedback.
- Ensuring Scalability and Robustness: Configure the retrieval module to handle growing datasets and increased query loads without compromising performance. Implement caching mechanisms, load balancing, and distributed architectures to support scalability. Additionally, establish monitoring and logging systems to ensure the module’s reliability and robustness.
Step 3: Setting Up the Generation Module
For the generation module, a transformer-based model is recommended. Models like BERT, GPT-3, or their derivatives are well-suited for this task. Fine-tune the model using your dataset to ensure it generates responses that are coherent and contextually relevant.
- Selecting a Generative Model: Choose a transformer-based model that aligns with your application needs. Consider factors such as model size, inference speed, and adaptability to domain-specific data. Models like BERT are effective for context-sensitive tasks, while GPT-3 offers advanced language generation capabilities.
- Fine-Tuning and Customization: Fine-tune the generative model on your specific dataset to enhance its performance and relevance. This involves training the model on domain-specific examples, adjusting hyperparameters, and incorporating additional context or constraints to guide the generation process.
- Balancing Creativity and Accuracy: Strive to maintain a balance between generating creative and engaging responses while ensuring factual accuracy. Implement mechanisms for content validation, bias mitigation, and error correction to uphold the quality and reliability of the generated outputs.
Step 4: Integration and Testing
Once both modules are configured, integrate them using a robust integration layer. This layer should efficiently manage data flow between the retrieval and generation components. Conduct rigorous testing to ensure the pipeline functions seamlessly and accurately.
- Designing the Integration Layer: Develop an integration layer that facilitates smooth communication between the retrieval and generation modules. This involves designing APIs, data exchange protocols, and error handling mechanisms to ensure seamless interactions.
- Testing for Seamless Operation: Perform comprehensive testing to validate the pipeline’s functionality and accuracy. This includes testing various query types, data scenarios, and edge cases to ensure the pipeline handles diverse inputs effectively and produces coherent outputs.
- Monitoring and Feedback: Implement monitoring systems to track the pipeline’s performance and gather feedback for continuous improvement. Analyze performance metrics, user feedback, and error logs to identify areas for enhancement and optimization.
Step 5: Optimization and Fine-Tuning
Optimization is critical for enhancing the pipeline’s performance. Regularly monitor the pipeline’s output, tweaking retrieval algorithms and fine-tuning the generative model to improve accuracy and coherence. Implement feedback loops to continuously refine the pipeline based on performance metrics.
- Continuous Performance Monitoring: Establish a monitoring framework to track the pipeline’s performance in real-time. This involves logging key metrics, analyzing response times, and identifying bottlenecks or inefficiencies in the pipeline’s operation.
- Algorithm and Model Refinement: Regularly review and refine the retrieval algorithms and generative models to enhance performance. This includes updating parameters, incorporating new data, and leveraging advancements in NLP techniques and technologies.
- Incorporating Feedback for Improvement: Implement feedback loops to gather user feedback and performance data for ongoing improvement. Use this information to make informed adjustments, optimize processes, and ensure the pipeline continues to meet evolving needs and expectations.
Practical Applications of the RAG Pipeline
The RAG pipeline’s versatility makes it applicable across various domains. Here are a few examples:
- Customer Support: Automate responses to customer queries, enhancing response accuracy and reducing response times. The RAG pipeline can handle diverse customer inquiries, providing personalized and contextually relevant information, thereby improving customer satisfaction and operational efficiency.
- Content Generation: Aid in the creation of contextually rich and informative content for blogs, articles, and reports. The RAG pipeline can generate content that is engaging, accurate, and tailored to specific audiences, supporting content creators in producing high-quality materials with reduced effort.
- Academic Research: Facilitate the synthesis of information from vast academic databases, assisting researchers in literature reviews and data analysis. By retrieving and summarizing pertinent academic content, the RAG pipeline can accelerate research processes, enabling researchers to focus on critical analysis and innovation.
Challenges and Considerations
While the RAG pipeline offers numerous benefits, several challenges must be considered:
- Data Quality: The quality of your dataset directly impacts retrieval and generation accuracy. Ensure your data is clean, structured, and relevant. Implement data validation, cleaning, and enrichment processes to maintain high data quality standards.
- Computational Resources: The dual-phase architecture of the RAG model requires significant computational power. Optimize resource allocation to balance performance and cost. Consider leveraging cloud computing, distributed systems, and hardware acceleration to meet computational demands efficiently.
- Ethical Considerations: Ensure that your model adheres to ethical standards, particularly in terms of data privacy and bias mitigation. Implement measures to protect sensitive information, eliminate biases, and uphold ethical guidelines, fostering trust and compliance in your RAG pipeline deployment.
Conclusion
The RAG pipeline stands as a cutting-edge solution in the field of NLP, marrying the precision of retrieval with the creativity of generation. By meticulously setting up and optimizing this pipeline, you can harness its full potential, driving advancements in automation, content creation, and information synthesis. Embrace this powerful tool to revolutionize your approach to data processing and natural language understanding. As you deploy and refine your RAG pipeline, remain committed to innovation, ethical practices, and continuous improvement to maximize its impact and value.